
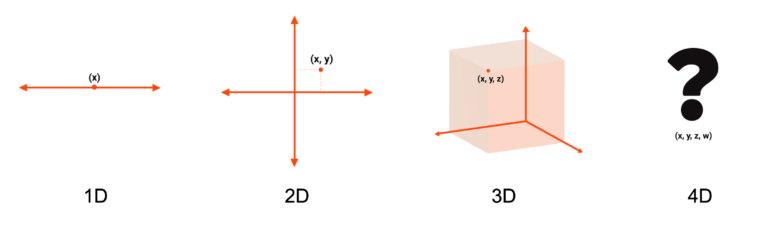
Most common way of categorizing time-series data is by the number of feature variables: (1) univariate time-series, (2) multivariate time-series.
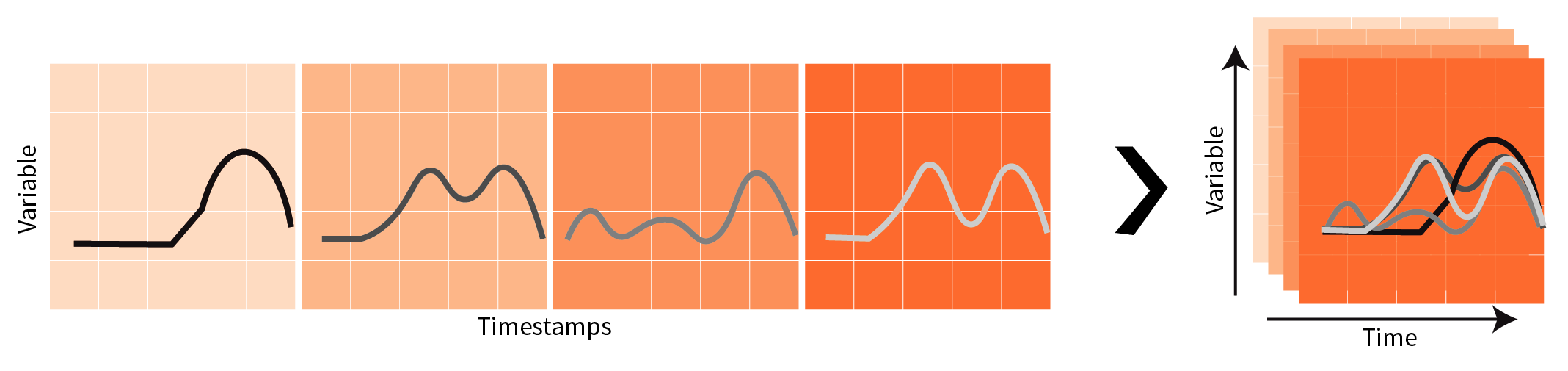
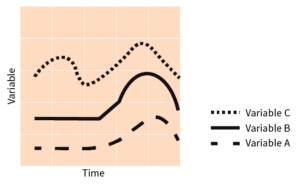
Univariate time-series capture the trend of one variable over time; whereas multivariate time-series can provide insight into the relationships amongst different variables.
Depending on the consistency of sampling rate, time-series data can be categorized into metrics and events.
Biometric data such as heartrate, financial performance data, or sensor data from manufacturing equipment collected over a fixed time period are all examples of metrics.
Bank deposit and withdrawal history and the number of daily tweets in the US are examples of event data – data in which there is no time correlation between events.
Regularly samples metric data can be further described as discrete or continuous.
Discrete time-series data are metric data collected on a finite sampling interval; on the other hand, continuous data have infinitely small sampling intervals.
Since computers digitize data, they cannot store continuous time-series. Theerefore, when it comes to computer-based time series analysis, continuous time series data are not relevant concepts.

